
Продуктовый аналитик: Путешествие туда и обратно
Глава 2. Кузница оружия
2.5. Excel и GoogleSheets - ваш надежный Походный Набор
Наставник даёт вам первые инструменты. Здесь, в грохоте ETL-процессов и мерцании строк кода, вы куете своё оружие для будущих битв в загадочном и прекрасном мире аналитики больших данных.
- Excel и GoogleSheets навсегда захватили мир
- Чем хорош Google Sheets
- Полезные функции (VLOOKUP, IMPORTRANGE, REGEX, SUMIFS и другие)
- А/В тест (T-тест, U-тест, Z-тест, p-value)
- Подводные камни
- Датасет для отработки формул
2.5.1. Excel и GoogleSheets захватили мир
Если ты только начинаешь свой путь в игровой аналитике, у тебя наверняка есть ощущение, что «настоящий анализ» начинается там, где царит мир BigData, SQL, Python, Spark, Data Science, DWH и BI-систем. А Excel или Google Sheets уже пережиток прошлого, игрушки для бухгалтеров и стажеров. Конечно, хороший аналитик должен писать сложные запросы, ставить пайплайны на расписание и строить модели на Python. Но в реальной жизни, особенно в игровой разработке, 50% твоей работы это ответы на вопросы, которые не терпят отлагательств. Тогда простые и надежные таблички в Excel или GoogleSheets становятся твоим «Универсальным Походным Набором» в коммуникации с продюсерами, геймдизайнерами и маркетингом.
Продюсер заходит через 5 минут после созвона руководством: «Слушай, а сколько аудитории к нам приходило в прошлом году по бесплатным каналам? Можешь дать мне данные по неделям и сгруппировать их по ГЕО? Этих срезов нет в дашборде, а мне необходимо подготовить срочно презентацию для руководства».
Передать продюсеру криво сделанную выгрузку в формате CSV или скинуть ему код SQL чтобы он сам посчитал что ему нужно, а тем более делать дашборд для разовой задачи чистое самоубийство. Таблицы Excel или GoogleSheets дают скорость и совместимость с тем же PowerPoint.
-
Python, витрины и пайплайны, и BI нужны для систем, которые надежно работают годами: дашборды Retention и мониторинг состояния проекта, прогнозы LTV и ROAS. Это важно и нужно на регулярной основе.
-
Excel или GoogleSheets нужны для быстрых сводок (ad-hoc аналитики). Это разовые или регулярные, но небольшие отчеты, где важна скорость получения инсайта и возможность заказчику самому «пощупать» данные руками. «Пощупать» это не просто дать доступ, но и сделать вашу таблицу аккуратной, понятной и проверяемой. Обязательно оставляйте комментарии к сложным расчетам или неочевидным формулам (ПКМ «Вставить примечание»).
-
Мир продюсеров, геймдизайнеров и маркетинга это часто царство большого числа таблиц. Продюсеры считают в табличках бизнес-модель проекта, рассчитывая выручку и маржинальность, геймдизайнеры делают в табличках калькулятор баланса и экономики, специалисты по монетизации считают новую акцию или распродажу, маркетологи контролируют бюджеты на закупку трафика, финансисты ведут там всю финансовую отчетность.
Если аналитик соберет быструю сводку в Excel или Google Таблицах, то заказчик может сам легко перенести это в свои формы и даже случайно ничего не сломать. Excel и Google Таблицы давно и, вероятно, навсегда захватили все компьютеры в мире.
2.5.2. Чем хорош Google Sheets
Многие считают Google Sheets «облегченной версией Excel». Это не совсем так. Несмотря на то, что построение графиков в Sheets может превратиться в настоящую пытку, у Sheets есть «суперспособности».
-
Простой доступ и синхронная работа команды с одним общим документом через браузер, авто обновление таблиц на основе других источников. Встречалось ли у вас, когда вы отправили файл, все его пересохранили и у каждого в команде есть своя версия исправлений, а вам как аналитику нужно сопоставить их все чтобы убрать противоречия, а затем собрать на их основе общий файл? Можно забыть про такое. Выдавайте права на ваш документ по ссылке тем кому необходимо.
-
Google Apps Script (JavaScript). Вы можете автоматизировать рутину. Например, настроить автоматическую выгрузку из различных источников, включая Google Analytics, и отправку в другие таблицы или, например, отчет в Telegram/Slack.
-
Google Sheets подключается напрямую к BigQuery через Connected Sheets. Продюсер получает интерфейс, где мышкой выбирает «Вчерашний LTV по Андроиду», а Sheets выполняет запрос к базе данных, не нагружая свой комп. Это идеальный способ дать бизнесу доступ к большим данным без SQL.
2.5.3. Полезные функции
Для многих кто считает, что знает Excel, функции ограничиваются формулами типа =sum() или =average(). В реалиях геймдева этого катастрофически мало. Например, вам может понадобится формировать документацию по логам, вытаскивая названия ивентов из грязных логов, или быстро группировать когорты для продюсера, который хочет «всё и прямо сейчас».
Именование диапазонов
При написании формул вы можете обращаться к диапазону ячеек, указывая с какой ячейки и по какую в виде $E$3:$E$8, или задать диапазону читаемое имя (в Excel: Формулы → Диспетчер имён; в Sheets: выделите диапазон и введите имя в поле слева от строки формул). Формула =SUMIFS(users; platform; G3; cohort_start; H3) читается несравнимо лучше, чем набор диапазона ячеек и постоянное использование знаков доллара.
VLOOKUP, INDEX/MATCH
Один из важных навыков это умение объединять данные нескольких табличек. В SQL мы ранее использовали JOIN., а в Excel и Sheets есть его аналог - функции поиска. VLOOKUP ищет значение в первом столбце диапазона и возвращает значение из заданного столбца той же строки:
=VLOOKUP(значение_которое_ищем; таблица_где_ищем; номер_столбца_в_таблице; 0)
Последний аргумент 0 (или FALSE) означает искать только точное совпадение, почти всегда нужен именно он.
Предположим, у нас есть таблица с платежами игроков (player_id в колонке с ячейки A2, и payment_amount) и справочник с ГЕО наших игроков (player_id в колонке H и country в колонке I). Вам необходимо подтянуть страну из справочника.
=VLOOKUP(A2; $H:$I; 2; 0) - сделай поиск значения player_id в колонке с ячейки A2, ищи такое значение в диапазоне $H:$I, подтягивай при совпадении значение из колонки 2, совпадение должно быть точным (0).
Главный минус функции VLOOKUP это то, что он ищет совпадение только по крайнему левому столбцу таблицы. В нашем примере выше поиск совпадения это самая левая колонка диапазона H. Но функция INDEX/MATCH лишена этого ограничения и работает быстрее на больших диапазонах.
=INDEX(диапазон_результата; MATCH(значение_которое_ищем; диапазон_поиска; 0))
В Google Sheets также доступна функция =XLOOKUP(), которая объединяет удобство VLOOKUP и гибкость INDEX/MATCH.
IMPORTRANGE
Когда у вас есть несколько связанных таблиц Google Sheets есть отличный синхронизировать изменения в них, когда, например, продюсер обновляет данные по маркетингу в одной таблице, а ваша итоговая сводка в другой таблице меняется сама. Это означает конец эпохи скачанных файлов, отслеживания изменений и регулярного ручного обновления столбцов. Вы просто пишете формулу у себя, и в вашей таблице данные обновляются как только внесут изменения на источнике-доноре.
=IMPORTRANGE("url_таблицы_донора"; "диапазон")
url_таблицы_донора- это ссылка на Google-таблицу, откуда вы хотите взять данные. Её нужно обязательно заключать в кавычки.диапазон- это адрес ячеек, которые вам нужны для импорта, тоже в кавычках. Он пишется в формате"название_листа!A1:B10". Если не указать название листа, функция будет искать данные на первом листе документа.
Например:
=IMPORTRANGE ("https://docs.google.com/spreadsheets/d/1sOewZq6FW3vA93E_eJDMWtssb3V6UDW3O1VTmj9RMNQ/edit?gid=0#gid=0"; "Февраль!A2:C100")
Если у вас есть доступ к вашей итоговой таблице, но нет доступа к таблице-донору, то IMPORTRANGE работать не будет. Вам придётся запросить права у владельца таблицы которую вы хотите переносить к себе.
Регулярные выражения REGEX
Игровые логи особенно неизвестного вам проекта без документации это обычно грязная JSON-подобная строка. Например: [2026-02-21] event:"level_start", level:"3", player:"id_123", item:"sword_rare". Чтобы привести это к табличному виду незаменимы регулярные выражения (Regex). Это язык поиска по шаблону.
Обратите внимание на конструкцию ключ:\""([^\""]+)" это выражение ваша шпаргалка. Можете ее просто записать и использовать.
=REGEXEXTRACT(A1, "level:\""([^\""]+)") вытащим значение из кавычек после level
Но можно попробовать разобраться как работает вся эта хитрая формула:
- JSON из примера это набор пар "ключ:значение", разделенных запятыми, а значения взяты в двойные кавычки;
- указание level: это якорь, который показывает, где начинается интересующая нас информация;
- \"" – указывает, что мы ищем последовательность вида level: + " ;
- ([^\""]+) – захват необходимого выражения, круглые скобки () означают, что то что внутри считать результатом
- [^\""] - символьный класс с отрицанием. Квадратные скобки [] означают “любой символ из перечисленных”. Но если первым идет крышечка ^ внутри скобок, это означает “любой символ, КРОМЕ перечисленных”. То есть [^\""] означает: “любой символ, кроме двойной кавычки”.
- + означает “один или более раз”. То есть мы ищем последовательность из одного или более символов, которые не являются кавычками.
Логические конструкции
Ранее мы уже пробовали строить когортный анализ и использовать сводные таблицы (Pivot Tables). В Excel есть для этого полноценный функционал, но часто можно использовать простые и более гибкие конструкции.
Как альтернатива сводным таблица, простые SUMIFS (и его братья COUNTIFS, AVERAGEIFS, MAXIFS) позволяют создавать динамические отчеты, которые обновляются мгновенно при изменении исходных данных и могут быть встроены в любую структуру дашборда.
Синтаксис SUMIFS
Например, нам необходимо провести когортный анализ удержания новых игроков в игре. Для этого будет необходимо суммировать значения по одной из колонок, но только если выполняется несколько условий.
=SUMIFS(диапазон_суммирования; диапазон_условий1; условие1; [диапазон_условий2; условие2]; ...)
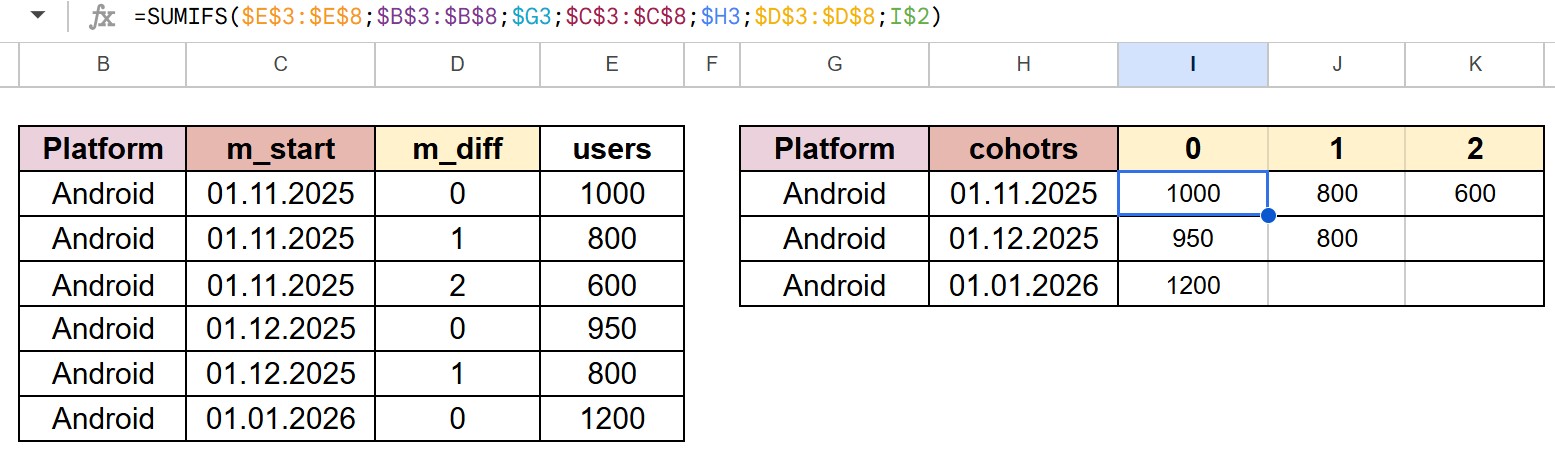
Важно, что в похожей функции SUMIF, где проверяется только одно условие, первым аргументом идет условие, а не диапазон суммирования. Это частая ошибка.
Предположим, исходные данные это таблица с колонками platform (платформа), m_start (месяц старта когорты), m_diff (месяц жизни когорты), users (количество игроков). Необходима сводная таблица, где когорта это платформа и месяц старта, столбцы – это месяцы жизни когорты, а значения – численность.
Итоговую формулу можно растянуть на всю таблицу
=SUMIFS($E$3:$E$8;$B$3:$B$8;$G3;$C$3:$C$8;$H3;$D$3:$D$8;I$2)
Обратите внимание на символ $. С его помощью при растягивании формулы на всю таблицу можно зафиксировать строки и/или столбцы (можно не вводить $ с клавиатуры, а перещелкивать кнопку F4).
- $E$3:$E$8 – диапазон суммирования фиксирован (колонка users)
- $B$3:$B$8 – диапазон условия 1, фиксирован (колонка platform), тут будем искать совпадение по условию 1;
- $G3 – условие 1, фиксирован только столбец, потому что при протягивании формулы значение строки должно изменится на следующее (например, G1 -> G2 и т.д.)
- и далее аналогично проверяем cohorts и m_diff.
Как видите, формула достаточно просто расшифровывается. Из плюсов, ваша сводная таблица справа мгновенно обновляется при изменении исходных данных.
Базовые операции с датами
В Excel и Sheets дата это число. 1 января 1900 года = 1, каждый следующий день +1. Это означает, что с датами можно делать арифметику: =B2 - A2 даст количество дней между двумя датами.
Ключевые функции для работы с датами:
=TODAY() - сегодняшняя дата
=DATEDIF(A1; B1; "D") - количество дней между датами (M или Y - месяцев или лет, если использовать их в формуле вместо D)
=EOMONTH(A1; 0) - последний день месяца для даты в A1
=WEEKNUM(A1) - номер недели в году
=TEXT(A1; "MM-YYYY") - преобразовать дату в текстовый формат “месяц-год”.
Функция =TEXT(A1; "YYYY-MM") особенно полезна для группировки по месяцам: она превращает любую дату в строку “2026-02”, по которой удобно делать SUMIFS.
2.5.4. А/В тест
Кажется, что аналитики, которые редко делали настоящие исследования поведения аудитории, возвели вокруг А/В тестов целый культ. Отдельно мы пройдем по всему необходимому функционалу A/B тестов, а сейчас рассмотрим только основы. Но как вы увидите ниже, ваш Excel или Google Sheet легко справится с простыми случаями обработки А/В тестов.
А/В тест (или сплит-тест) - это эксперимент, в котором мы сравниваем контрольную (А) и тестовую (В) версию продукта, чтобы понять, какая из них лучше влияет на целевую метрику.
Предположим, ваш гейм-дизайнер предлагает добавить таймер с обратным отсчетом времени в бандлы для игроков. Гипотеза: таймер с обратным отсчетом создает ощущение срочности и увеличит нашу выручку. Пусть, вы случайным образом разделяете игроков на две группы и показываете части из них измененный вариант. После некоторого периода вы оцениваете результаты. У вас есть файл с платежами каждого игрока за период теста.
Подготовка данных
Перед анализом теста проверьте данные на аномалии. Например, когда один игрок с платежом 10000$, в то время как обычно максимальный донат 100$.
Пусть результаты выглядят примерно так:
- Группа А: 1490 человек по 0$, 10 человек по 10$ (среднее = 100/1500 = 0.066$)
- Группа B: 1545 человек по 0$, 4 человека по 10$ и 1 человек (кит) на 500$ (среднее = (40+500)/1550 = 540/1550 = 0.348$)
Выбираем правильный статистический тест
- T-тест (Стьюдента) это параметрический тест. Он сравнивает средние значения двух групп, если данные распределены «нормально».
- U-тест (Манна-Уитни) это непараметрический тест. Он сравнивает распределения двух групп (по сути, проверяет, смещена ли одна группа относительно другой).
Чаще всего выбирают обычный t-тест, но сейчас это ошибка. Платежи (или, например, время в игре) НИКОГДА не распределены нормально. У вас огромное количество нулей (игроки, которые не платили), и распределение имеет скошенный вид. Так что используйте U-тест Манна-Уитни, либо можно применить некоторые приемы которые рассмотрим в отдельной главе – логарифмирование или разбивку по бакетам. В Google Sheets есть встроенная функция для T-теста и U-теста.
T-тест (неподходящий в нашем случае)
=T.TEST(массив_А; массив_B; 2; 3)
- 2 это вариант двухвыборочного теста, проверяем отличаются ли группы в большую или меньшую сторону.
- 3 это двухвыборочный тест с неравными дисперсиями, частый случай.
U-тест Манна-Уитни (в Google Sheet)
=MANNWHITNEY(массив_А; массив_B)
Предположим, мы получили двумя тестами разные результаты p-value:
- T-тест: p = 0.032. T-тест сравнил среднее и сразу обнаружил, что в группе B среднее выше в 5 раз, это очень значимая разница средних значений!
- U-тест: p = 0.21. Сопоставил отранжированное распределение в выборках. В группе А 10 платящих, в группе B 5 платящих. Медианы вообще одинаковые (и равны 0). Между выборками разница не обнаружена.
Ваш ответ будем звучать примерно так
«Несмотря на кажущийся рост среднего чека за счет одного крупного платежа, статистический тест (Манна-Уитни) показывает, что распределение платежей в группах не изменилось (p=0.21). Мы не можем утверждать, что добавление таймера с обратным отсчетом времени в бандлы для игроков работает лучше. Рекомендуем оставить прежний вариант и тестировать другую гипотезу.»
Как интерпретируют p-value
| Значение p-value | Что это значит на человеческом языке | Действие |
|---|---|---|
| p < 0.05 | Вероятность ошибиться меньше 5%. Различие есть, и оно не случайно. | Можно внедрять изменение (если оно в плюс). |
| p > 0.05 | Мы не можем отвергнуть гипотезу о том, что различий нет. Тест не показал значимого эффекта. | Изменение не работает. Ищем другую гипотезу. |
| p ≈ 0.05 (0.045 - 0.055) | Серая зона. Результат на грани. | Нужно увеличить размер выборки и проверить еще раз. |
Важно, что если вы проводите несколько A/B тестов одновременно или проверяете одни и те же данные по множеству метрик, вероятность случайно получить p < 0.05 хотя бы в одном тесте резко возрастает. При 20 одновременных тестах вы ожидаемо получите одно «значимое» различие чисто случайно. Поправка Бонферрони (делите 0.05 на количество тестов) это простейший способ контролировать эту проблему.
Z-тест для пропорций
К сожалению, если нам необходимо провести тест по сопоставлению конверсий в Google Sheets придется записать формулу этого теста вручную.
Поскольку в нулевой гипотезе мы предполагаем, что конверсии равны, мы объединяем данные обеих групп для получения более точной оценки общей конверсии:
p = (x₁ + x₂) / (n₁ + n₂)
Где:
- x₁, x₂ — количество “успехов” в каждой группе,
- n₁, n₂ — размеры групп,
- тогда p₁=x₁/n₁ и p₂=x₂/n₂ .
Затем рассчитываем Z-статистику:
z = (p₁ - p₂) / √[p * (1-p) * (1/n₁ + 1/n₂)]
Чем больше абсолютное значение Z, тем меньше вероятность, что разница случайна.
Например, мы тестируем новый туториал для новичков:
- Группа А (контроль): 1000 игроков, конверсия 12%
- Группа B (тест): 1050 игроков, конверсия 14,3%
Результаты расчетов:
- Объединенная пропорция: (120+150)/(1000+1050) = 270/2050 = 0,1317
- Z-статистика: (0,12 – 0,143)/0,0151 = -1,52
- Для двустороннего теста p-value равно 2*(1 - NORM.S.DIST(ABS(-1,52), TRUE)) = 0,128
В нашем примере p-value (0.128) > 0.05 → разница статистически не значима. Несмотря на визуальный рост с 12% до 14.3%, мы не можем утверждать, что новый туториал работает лучше.
2.5.5. Подводные камни Google Таблиц и Excel
Самая страшная проблема большого числа табличек это человеческий фактор.
Защита листов и диапазонов
В Sheets Данные -> Защищенные листы и диапазоны. Настройте, кто может редактировать конкретные зоны. Продюсеру оставьте только “поля ввода”, а расчетную часть заприте на замок.
Скачал и все сломал
В Excel классическая проблема, когда вы отправили файл по почте, а получили обратно от разных заказчиков несколько версий с суффиксами примерного такого вида “new_ final _3” или “last_ver _2”, ваши действия?
В Sheets общий доступ к одной версии и есть история изменений (Файл -> История версий). Там можно посмотреть, кто и когда испортил данные, и откатиться назад.
Закрепить формулу при протягивании
Вы написали формулу =A1*B1, протянули вниз, а она превратилась в =A2*B2. Это относительные ссылки. Но когда вы протягиваете формулу вбок или вниз, а ссылка должна оставаться на конкретную ячейку (например, на курс валюты), начинаются проблемы. Чтобы закрепить строку или столбец при протягивании используем $.
- A1 - не закреплено;
- $A$1 – полностью закреплено;
- $A1 - столбец закреплен, строка меняется;
- A$1 - строка закреплена, столбец меняется.
Клавиша F4 (на Windows) или Cmd + K (на Mac) в Excel и Sheets мгновенно переключает типы, если вам не хочется вбивать знак $.
Неявные типы данных
Если столбец с числами вдруг начал выравниваться по левому краю это сигнал вам, что Excel или Sheets решили, что это текст. Функция =VALUE() принудительно конвертирует текст в число. В обратную сторону =TEXT(A1; "0.00") превращает число в текст с нужным форматированием.
Все тормозит
Это точно произойдет уже при 100К строк. Вы слишком увлеклись, работая только в Excel и Sheets, вам давно пора переходить в другие инструменты. Добро пожаловать в Power BI или Tableau! Они созданы для работы с миллионами и даже миллиардами строк.
Excel и Sheets это инструменты быстрой коммуникации
Не будьте снобами. Не нужно мучить Excel там, где нужен DWH и SQL. Но и бежать в Python или строить дашборд, чтобы просто посчитать конверсию из регистрацию во вход в игру это глупо. Будьте гибче. Вы должны уметь написать сложный запрос на SQL, но при этом не брезговать быстрым расчетом в Excel. Вы должны уметь строить модели на Python, но отдавать продюсеру вы будете понятную табличку с комментариями.
Как аналитик вы умеете видеть за сухими цифрами живых игроков, так и за рабочими задачами вы должны видеть живые потребности ваших коллег из команд разработки игры, маркетинга, продюсеров. Excel и Google Sheets это твой «Универсальный Походный Набор» в коммуникации с бизнесом. И чем свободнее вы им владеете, тем ценнее ваш голос в общей команде.
Учебный датасет
https://disk.yandex.ru/d/9rkEZH01sJ3bJA
Состав данных
1500 строк, 583 уникальных игрока (от 1 до 10 записей на игрока)
Платформы: Android (58%) / iOS (42%)
15 стран, период установок: январь 2024 — июнь 2025
Выручка: $21 248, максимальный платёж: $999.99, «китов» (≥$250): 21
Что можно отработать
| Задача | Формула |
|---|---|
| Суммарная выручка игрока | SUMIF по player_id |
| Первый платёж игрока | MINIFS(payment_date; player_id; "p_200001") |
| Выручка по платформе за месяц | SUMIFS + TEXT(install_date; "YYYY-MM") |
| Количество платежей на игрока | COUNTIF по player_id |
| Дней от установки до первой оплаты | MINIFS(payment_date; ...) минус install_date |
| LTV когорты по месяцу установки | SUMIFS + группировка по TEXT(install_date; "YYYY-MM") |
| Поиск «китов» | MAXIFS по стране или платформе |
| Сравнить платежи iOS vs Android | U-тест Манна-Уитни |