
Продуктовый аналитик: Путешествие туда и обратно
Глава 2. Кузница оружия
2.3. Меч Героев: SQL как ваше основное оружие
Наставник даёт вам первые инструменты. Здесь, в грохоте ETL-процессов и мерцании строк кода, вы куете своё оружие для будущих битв в загадочном и прекрасном мире аналитики больших данных.
-SQL это язык общения с данными
-Основные конструкции SQL
-CTE
-Оконные функции
-DDL
2.3.1. SQL это язык общения с данными
SQL (Structured Query Language) это декларативный язык программирования для работы с реляционными базами данных. В отличие от императивных языков, где вы описываете как выполнить задачу, в SQL вы описываете что хотите получить, а система оптимизации запросов сама определяет наиболее эффективный способ выполнения.
SQL это ваш «Меч Героев» - основное оружие в будущих битвах в загадочном и прекрасном мире аналитики больших данных. Это основной протокол общения между специалистами по данным и самими данными.
-Универсальность. От сырых логов до агрегированных витрин вы взаимодействуете с данными через SQL.
-Декларативность. Вы описываете «что» нужно получить (например, «топ-10 игроков по донату за последнюю неделю»), а СУБД (BigQuery, PostgreSQL, Snowflake) сама решает «как» это эффективно выполнить, используя свои оптимизаторы.
-Стандартизация. Освоив один диалект, вы легко адаптируетесь к другим, что критично в быстро меняющейся экосистеме данных.
2.3.2. Основные конструкции SQL
Предположим, нам надо на основе таблицы game_events посчитать сумму потраченных игровых монет каждым игроком с первого января 2024, а затем отсортировать результаты по игрокам от большего к меньшему по полученным суммам.
В запросе ниже обратите внимание на элементы, выделенные в коде жирным шрифтом. Они как конструктор формируют инструкцию сборки того, что мы хотим получить.
Старайтесь при написании SQL придерживаться правил форматирования запроса как в примерах.
SELECT user_id, SUM(purchase_amount) AS total_spent
FROM game_events
WHERE event_date >= '2024-01-01'
GROUP BY user_id
ORDER BY total_spent DESC
Что значат элементы этой конструкции
SELECT это “что мы хотим увидеть”
-Выбираем какие колонки попадут в результат (в примере их две).
-Как они будут называться (переименование происходит через AS, который, впрочем, можно и пропустить).
-Какие вычисления произойдут (в нашем примере это суммирование).
-Можно добавить логические конструкции типа «если – то» в виде CASE WHEN <условие> THEN <выражение1> ELSE <выражение2> END as <имя колонки>.
FROM это “откуда берем данные”
В нашем примере мы берем данные из таблицы с названием game_events
WHERE это “как фильтруем строки”
-Можно применять несколько правил через скобки, AND и OR.
-Можно использовать операторы равно (=), меньше/больше или равно (<=, >=), не равно (!=), похоже (like/ilike), пропущенные/не пропущенные значения (IS NULL / IS NOT NULL) и другие.
-Важно, что WHERE выполняется ДО группировки и агрегации, что позволяет сокращать объем обрабатываемых данных на раннем этапе. Обязательно фильтруйте здесь ваши большие данные по партициям!
GROUP BY указывает, что мы группируем по заданным полям, а для остальных применяем агрегирующие функции.
Обратите внимание, что сами агрегирующие функции записаны в SELECT, а в GROUP BY есть указания только поля, для которых производится группировка. Функция агрегирования пишется вместе со скобками, внутри которых должен быть указан аргумент функции, другими словами, к чему мы функцию применили.
Основные агрегирующие функции:
-COUNT(…) - подсчет количества строк
-COUNT(DISTINCT …) - подсчет количества уникальных значений
-SUM(…) и AVG(…) - сумма и среднее
-MIN(…) и MAX(…) - экстремумы
ORDER BY указывает порядок сортировки выдачи.
-В нашем примере сортировка производится от большего к меньшему (DESC), если вам необходима от меньшего к большему, то DESC писать не надо.
-Сортировать выдачу можно по нескольким столбцам последовательно. Для этого просто перечисляем их последовательно через запятую.
Есть еще крайне важная конструкция SQL запроса, которую надо рассмотреть отдельно. Предположим, в одной таблице (например, game_events) у вас есть предметы, которые начислены игроку после их покупки и transaction_id этой покупки, а в другой (например, game_ purchase) - размер каждой транзакции в игровой валюте и transaction_id покупки. Вам необходимо соединить две таблицы по общей колонке transaction_id.
JOIN объединяет данные из разных таблиц на основе логического условия.
В основе логики данных операций лежит реляционная алгебра и теория множеств. Если вы учились в техническом вузе, то обычно это входит в программу первого курса.
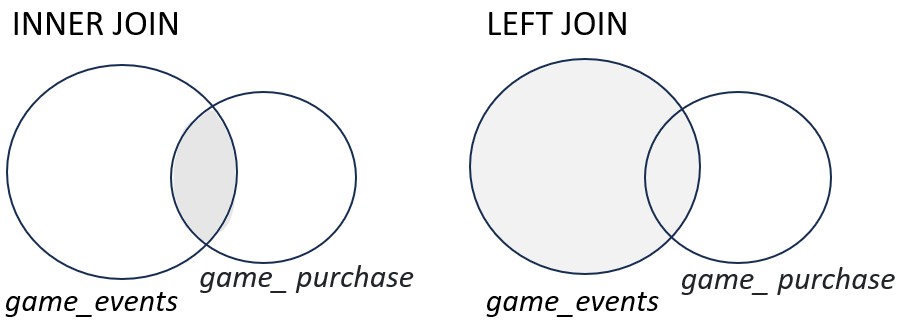
Основные типы JOIN.
-INNER JOIN – выбрать только те строки при сопоставлении таблиц, которые по логическому условию есть и в первой и второй таблице одновременно. Остальные строки из обоих таблиц выбрасываются.
-LEFT/RIGHT JOIN - сохраняем все из одной таблицы (если LEFT, то все из первой), и обогащаем их значениями из другой (если LEFT, то обогащаем из второй). Но обогащаем только для тех, у кого найдено соответствие по логическому условию, остальным по умолчанию будет подставляться пустое значение (NULL).
-FULL OUTER JOIN – сохраняем все из обеих таблиц, там где нет совпадения по логическому условию по умолчанию будет подставляться пустое значение (NULL)
Важно, что если в одной таблице будет одна строка для одного идентификатора по которому происходит объединение, а в другой - несколько строк (такой случай называют «связь один ко многим») то итоговое число строк при объединении увеличится. Ведь каждой строке из первой таблицы нашлось несколько строк из другой.
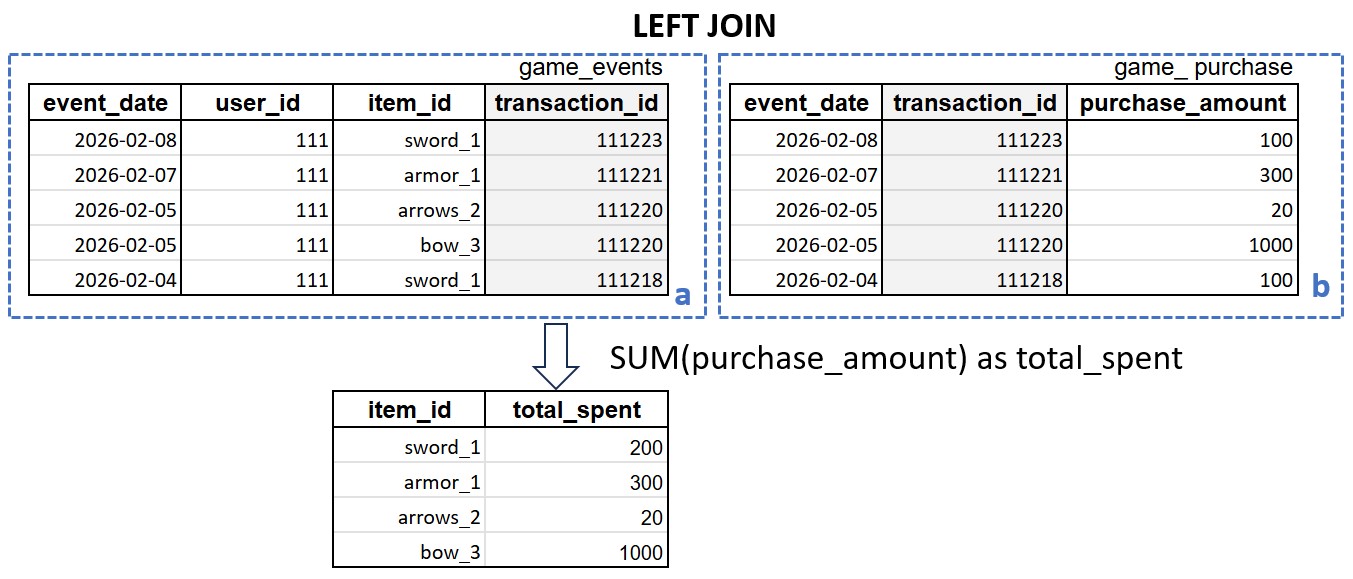
Теперь сформируем код SQL чтобы соединить две таблицы (game_events и game_ purchase) по совпадению transaction_id (строка ON a.transaction_id=b.transaction_id), а там где транзакции не найдены то подставляем «0» (функция COALESCE заменяет NULL). Обратите внимание, что когда необходимо указать название таблиц в логическом условии (в строке которая начинается с ON) то полученным промежуточным таблицам присвоены новые имена (в примере ниже это «a» и «b»).
SELECT item_id, COALESCE(SUM(purchase_amount),0) as total_spent
FROM
(SELECT event_date, user_id, item_id, transaction_id
FROM game_events
WHERE event_date >= '2024-01-01'
) AS a
LEFT JOIN
(SELECT event_date, transaction_id, purchase_amount
FROM game_ purchase
WHERE event_date >= '2024-01-01'
) AS b
ON a.transaction_id=b.transaction_id
GROUP BY item_id
Обратите внимание, что если запрос содержит JOIN то читать его надо «изнутри наружу», потому что выполняться он будет не по строкам, а сначала выполнит сборку промежуточной таблицы «a», потом «b», а потом их пересечение. Затем группировку по item_id и суммирование по purchase_amount, а полученная сумма называется total_spent.
2.3.3. CTE (Common Table Expressions)
Конструкция CTE применяется в SQL, когда необходимо создавать временные именованные таблицы и для структурирования сложных запросов. Они существуют только в рамках всего запроса. Такие временные таблицы удобны, когда нужно в запросе несколько раз переиспользовать результаты одного и того же запроса и, в целом, могут упрощать читаемость всего кода.
Конструкция CTE выполняется раньше всех и содержит блок вверху кода, который начинается с WITH и через запятую содержит временные именованные таблицы. В примере ниже мы делаем только одну временную таблицу «users» и потом в основном запросе извлекаем данные уже из нее.
WITH
users AS
(SELECT user_id, login_day
FROM logins
)
SELECT login_day, COUNT(DISTINCT user_id) as dau
FROM users
GROUP BY login_day
Для сравнения сделаем те же преобразования, но без CTE.

Использование CTE делает код самодокументируемым. Его легче читать, отлаживать и переиспользовать, чем вложенные подзапросы.
2.3.4. Оконные функции
Оконные функции это самый мощный инструмент SQL для аналитики, который позволяет выполнять вычисления над набором строк, связанных с текущей строкой, без свертывания данных в одну строку на группу. Используя оконные функции, вы можете провести анализ, сохраняя исходную детализацию таблицы.
Синтаксис в общем виде
функция(<аргумент>) OVER (PARTITION BY <по каким группам или "окнам"> ORDER BY <в каком порядке>)
PARTITION BY - делит данные на независимые окна или группы, внутри которых будут выполняться вычисления.
ORDER BY добавляется, когда окно становится “упорядоченным” - это ключ для скользящих и накопительных расчетов.
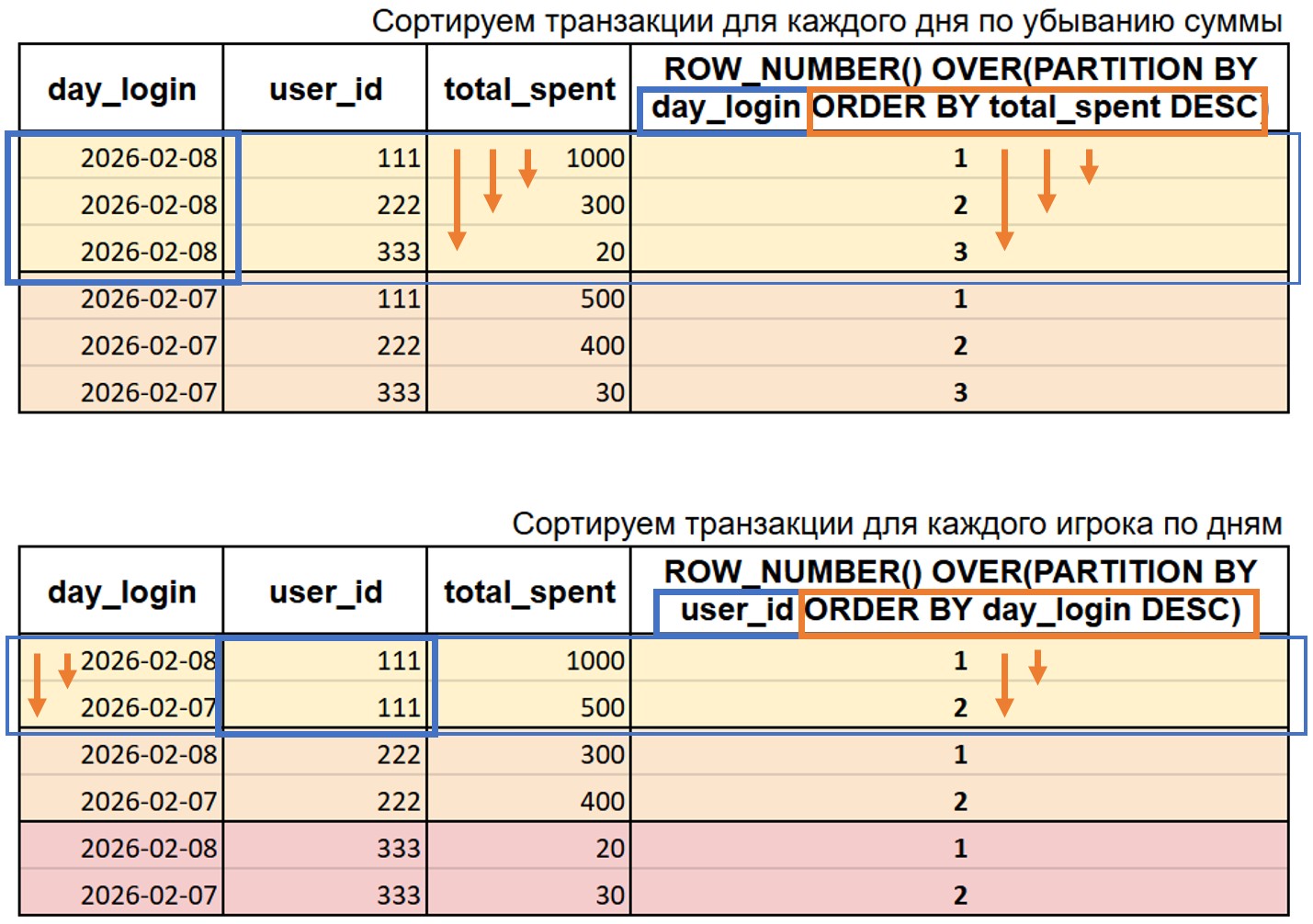
Например, мы хотим добавить еще один столбец, в котором за каждый день будут порядковый номер игроков отсортированных по сумме потраченных игровых денег. Сортировка будет от большего к меньшему, а окно в котором происходит расчет это день или day_login.
SELECT …, ROW_NUMBER() OVER(PARTITION BY day_login ORDER BY total_spent DESC)
На рисунке ниже в первой таблице качестве окна используется дата (day_login), во второй окно это user_id. Для удобства окно выделено синим, а оранжевым - сортировка внутри этого окна (по total_spent и day_login для первого и второго случая соответственно). В нашем случаем сортировка DESC то есть от большего к меньшему: в первой таблице от 1000 total_spent до 20, а во второй таблице - от 2026-02-08 до 2026-02-07.
Оконные функции:
-COUNT(…), SUM(…) и AVG(…), MIN(…) и MAX(…) уже знакомы (но COUNT(DISTINCT ...) не существует),
-ROW_NUMBER(), RANK(), DENSE_RANK() – ранжирование разных типов,
-LAG(), LEAD() - доступ к предыдущим/следующим строкам,
-FIRST_VALUE(), LAST_VALUE() - граничные значения окна,
-NTILE() - разбиение выборки после сортировки на равные по размеру группы (квантили).
Есть еще один необязательный элемент оконных выражений – граница окна (Frame Clause). Это самый сложный, но самый мощный элемент. Не страшно, если вы с первого раза не поймете как это работает.
Граница окна в оконной функции может быть динамической и мы можем определить, какие строки включаются в окно для каждой текущей строки.
Динамическое построчное окно
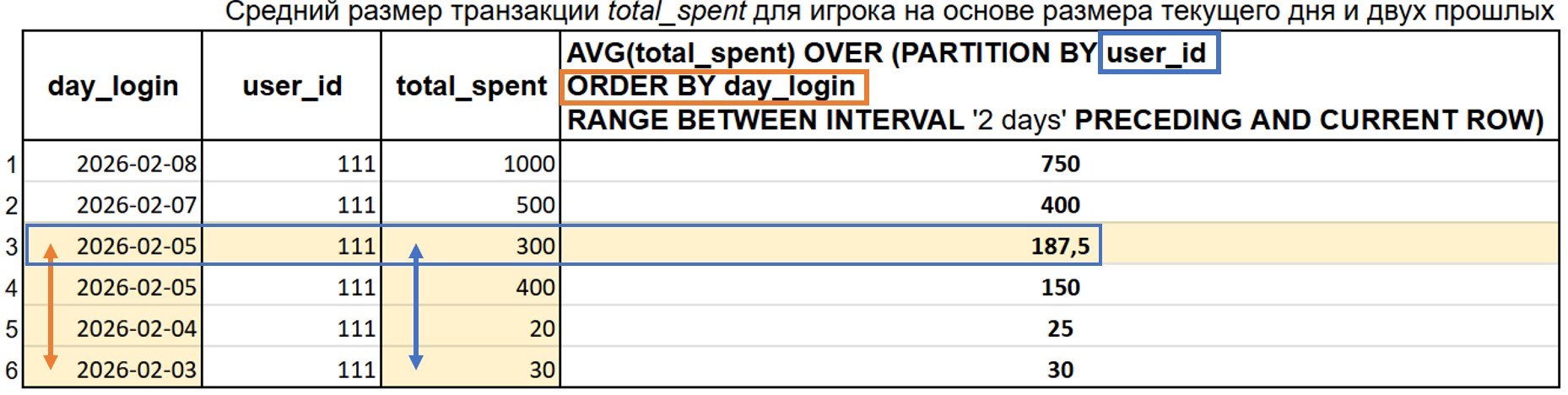
Например, для каждого игрока посчитаем средний размер транзакции с учетом двух его предыдущих транзакций (среднее за 3 строки, если строки считать на основе сортировки дат платежей)
AVG(total_spent) OVER (PARTITION BY user_id ORDER BY day_login ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
На рисунке ниже, для первой строки для расчета берут три строки 1, 2 и 3 (текущая и две предыдущие по day_login), а полученный результат это среднее (AVG(total_spent)) из трех чисел 1000, 500 и 300. Для второй строки для расчета среднего нужны строка 2, 3 и 4 (текущая и две предыдущие по day_login), а результат - среднее из 500, 300 и 400 (результат равен 400). Для третье строки (где результат это 240) были усреднены 300, 400 и 20 и т.д.

Возможно вы заметили, что игрок 111 совершает транзакции не каждый день, а в один из дней он заплатил дважды. Поэтому наше усреднение по трем строкам не равно среднему за три дня. Динамическое окно по диапазону как раз решает эту проблему.
Динамическое окно по диапазону значений
Посчитаем среднее по датам, не по строкам.
AVG(total_spent) OVER (PARTITION BY user_id ORDER BY day_login RANGE BETWEEN INTERVAL '2 days' PRECEDING AND CURRENT ROW)
На рисунке ниже можно увидеть отличия от прошлого результата. Например, для первой строки усреднение только по двум строкам вместо трех, потому что нет транзакции 2026-02-06. А для третьей строки (2026-02-05) усреднение происходит на основе четырех, а не трех как ранее. Но при этом для четвертой (2026-02-05) усреднение только на основе трех, хотя даты там одинаковые. Такой результат следствие указания на CURRENT ROW то есть с текущей строки, то есть код смотрит на текущую, отступает от нее 2 дня и ищет все строки которые укладываются в этот диапазон от текущей строки.
2.3.5. Оконные функции vs GROUP BY
Используй оконные функции когда:
-Нужно сохранить детализацию строк без агрегации
-Требуется сравнение строк между собой
-Необходимы ранжирование или нумерация (выбрать первое или последнее значение)
-Нужны скользящие/накопительные суммы
-Требуется доступ к предыдущим/следующим значениям (например, текущее минус предыдущее или последующее значение)
Выбирай GROUP BY когда:
-Нужна агрегация до уровня групп
-Требуется существенное уменьшение объема данных
-Будешь использовать результат в JOIN
Оконные функции - это не замена GROUP BY, а дополнение. Они решают другой класс задач: аналитику внутри групп без потери детализации. В BigTech оконные функции используются в 80% аналитических запросов. Освоив их, вы переходите от “простого извлечения данных” к “глубокому анализу”. Это тот навык, который отличает junior от senior аналитика.
2.3.6. DDL в SQL
DDL (Data Definition Language) - это подмножество SQL, отвечающее за создание, изменение и удаление структуры таблиц и базы данных. А до этого мы рассматривали другое подмножество SQL (DML или Data Manipulation Language) и работали с данными внутри таблиц.
Основные команды DDL
-CREATE TABLE - создание таблиц. Важно определение партиций (например, по event_date) для ускорения запросов в Big Data.
-CREATE VIEW / MATERIALIZED VIEW - виртуальные или материализованные (предрассчитанные) представления для упрощения доступа к сложным витринам.
-DROP, ALTER - удаление и изменение объектов.
- INSERT OVERWRITE table_name partition (partition_name)
SELECT ...- вставка перезаписью в таблицу table_name партиций partition_name на основании запроса который идет после select
Пример создания оптимизированной таблицы:
СREATE TABLE analytics.user_events_daily
(user_id INT64,
country STRING,
total_spent NUMERIC,
session_count INT64
) PARTITION BY (event_date STRING) – партицируем по дате, для BigData партиции в таблицах, как вы помните, это важно!
Без партиции код сканирует ВСЮ таблицу, а с партицией по дате при запросе с фильтром по where - читает только нужные даты. Разница в производительности может быть в тысячи раз!
Как второй пример, напишем начало кода который перезапишет часть таблицы analytics.user_events_daily которую мы создали ранее. Обратите внимание, что колонка по которой настроено партицирование указывается последней в select, и мы конвертируем колонки в тот же тип данных (функция cast()) который был использован в таблице при ее создании, и строго соблюдаем последовательность наших столбцов:
INSERT OVERWRITE analytics.user_events_daily PARTITION (event_date)
SELECT
cast(user_id as INT64) as user_id,
cast(country as STRING) as country,
cast(total_spent as NUMERIC) as total_spent,
cast(session_count as INT64) as session_count,
cast(event_date as STRING) as event_date
FROM ...
Немного советов как вам мастерски овладеть этим «Мечом Героев»
-Пишите чистый, красиво отформатированный код.
-Используйте CTE для сложных запросов.
-Всегда думайте о производительности (используйте партиции).
-Постоянно практикуйтесь. Каждый новый запрос это шаг к тому, чтобы превратить «загадочный мир больших данных» в источник четких идей для создания великих игр.